
In today’s era of digitalization, data has become the driving force behind most decisions and strategies made by businesses. From collecting customer data to analyzing market trends, data plays a crucial role in providing insights and improving overall business performance. However, with the vast amount of data being generated, it has become essential for companies to have an efficient and reliable system in place to manage and process this data. This is where data pipelines come into play.
A data pipeline is a series of processes that extract, transform, and load (ETL) data from different sources, such as databases, applications, or files, and then move it to a destination for storage or analysis. In simpler terms, it acts as a bridge between raw data and valuable information that can be used for decision-making. Data pipelines operate in real-time and automate the entire process, making it faster and more efficient compared to manual data handling.
Data pipelines have become an integral part of modern-day businesses, and their importance cannot be understated. In this article, we will dive deeper into the concept of data pipelines, their benefits, and how they are being used in various industries.
Overview of Data Pipelines
Data pipelines have been around for a long time, but with the exponential growth of data, their importance has only increased in recent years. In its simplest form, a data pipeline can be seen as a series of connected pipes through which water flows. Similarly, in the context of data, a pipeline is a series of processes that work together to extract, transform, and load data from various sources and deliver it to a destination.
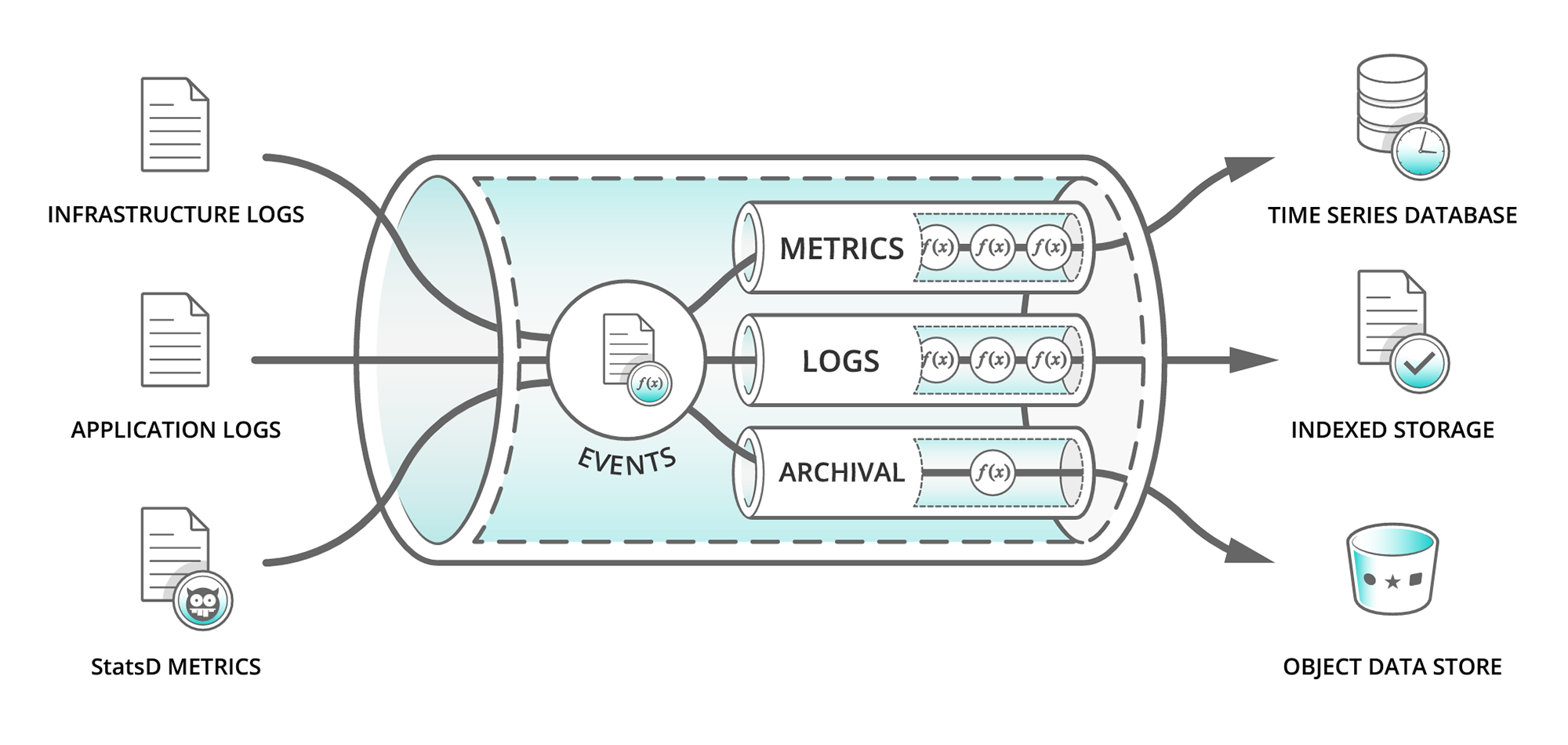
Data pipelines have existed for a considerable time, but their relevance has surged in recent years due to the exponential growth of data
The primary purpose of a data pipeline is to move raw data from its source to a place where it can be stored, analyzed, and used to derive valuable insights. This process is often referred to as ETL (extract, transform, load) and is an essential part of data management. Data pipelines use automation to speed up this process, making it more efficient and reliable compared to manually handling data.
How do Data Pipelines Work?
Data pipelines typically consist of three main stages: extraction, transformation, and loading. Let’s take a closer look at each stage.
Extraction:
In this stage, data is collected from various sources such as databases, applications, or files. The type and format of the data may vary, and it can be structured, semi-structured, or unstructured. Data extraction can be done in real-time or at scheduled intervals.
Data pipelines use connectors or APIs to extract data from different sources and bring it together in a centralized location. This ensures that all the data is stored in one place, making it easier to manage and analyze.
Transformation
Once the data has been extracted, it needs to be transformed into a usable format so that it can be analyzed. This involves cleaning and organizing the data, as well as converting it into a standardized format.
Data transformation can also involve merging data from different sources or splitting large datasets into smaller, more manageable chunks. This stage is essential to ensure that the data is accurate and consistent before it is loaded into the destination.
Loading
The final stage of a data pipeline is to load the transformed data into a destination, which could be a data warehouse, data lake, or a database. This data can then be used for analysis, reporting, or other purposes.
Data loading can be done in batch or in real-time, depending on the requirements of the business. Batch processing involves moving data in batches at scheduled intervals, while real-time processing moves data continuously as it is being generated.
Why are Data Pipelines Important?
Data pipelines play a crucial role in managing and analyzing data effectively. Here are some reasons why data pipelines are important in today’s digital world:
- Data pipelines enable fast and efficient data processing. With automation, data can be processed and analyzed in real-time, providing businesses with valuable insights faster.
- They improve data quality and reliability by eliminating manual processes that are prone to human error. Data pipelines follow a set of standardized rules and processes, ensuring that the data is clean and consistent.
- Data pipelines are scalable and flexible, meaning that they can handle large amounts of data from various sources without any issues. This makes them suitable for businesses of all sizes.
- They are cost-effective as they automate the entire process, reducing the need for human resources and minimizing the risk of errors. This makes data pipelines a more efficient solution compared to manual data handling.
- Data pipelines provide businesses with real-time analytics, allowing them to make faster and more informed decisions based on the latest data available.
Benefits of Using Data Pipelines
Data is the lifeblood of modern-day businesses, and data pipelines are essential in ensuring that this data is managed efficiently. Here are some benefits of using data pipelines:
Data is crucial for the operations of contemporary businesses, and data pipelines play a vital role in ensuring efficient management of this data
Real-time Processing and Analytics
One of the most significant advantages of data pipelines is the ability to process and analyze data in real-time. This enables businesses to stay up to date with the latest trends and make timely decisions based on accurate data.
Real-time analytics also allows businesses to monitor their performance and identify any issues or opportunities in real-time. This can be particularly beneficial in industries such as e-commerce, where customer behavior can change quickly.
Automation Leads to Improved Efficiency
Data pipelines automate the entire ETL process, making it more efficient and reliable compared to manual handling. With automation, businesses can save time and resources, allowing their employees to focus on more high-value tasks.
Automation also reduces the risk of human error, ensuring that the data is accurate and consistent. This leads to better decision-making and improved overall business performance.
Scalability and Flexibility
As mentioned earlier, data pipelines are scalable and flexible, meaning that they can handle large amounts of data from various sources. This is crucial for businesses that deal with ever-growing volumes of data, as traditional methods of data handling may not be sufficient.
Data pipelines can also be customized to fit the specific needs of a business, making them adaptable to different industries and use cases.
Cost-effectiveness
With automation and scalability, data pipelines can be a cost-effective solution for businesses. By eliminating manual processes and reducing the risk of errors, companies can save time and resources that can be allocated to other areas of the business.
Data pipelines also eliminate the need for investing in expensive infrastructure, as they can be implemented on existing systems and can handle large amounts of data without any additional hardware requirements.
Improved Data Quality and Reliability
Data pipelines follow set rules and processes, ensuring that the data is clean and consistent. This leads to improved data quality and reliability, which is crucial for making accurate business decisions.
With data pipelines, businesses can trust that the data they are analyzing is accurate and up to date, providing them with more reliable insights.
Types of Data Pipelines
There are three main types of data pipelines: batch, streaming, and hybrid. Each type has its own pros and cons, and businesses may choose one over the other depending on their specific needs.

The primary types of data pipelines include batch, streaming, and hybrid configurations
Batch Data Pipelines
Batch data pipelines involve moving data in batches at scheduled intervals. This means that data is processed and analyzed in chunks rather than in real-time. Batch processing is suitable for businesses that do not require real-time insights and can work with data that is a few hours or days old.
Pros:
- Batch processing is relatively easy to implement and does not require advanced technology or infrastructure.
- It is suitable for businesses that do not have strict real-time requirements and can work with data that is not up to date.
- It can handle large volumes of data without affecting system performance.
Cons:
- Batch processing cannot provide real-time insights, which may not be suitable for industries where timely decisions are crucial.
- It can lead to delays in data processing, which may affect the overall efficiency of the business.
- In case of any data issues, it may take longer to identify and fix them as data is processed in batches.
Streaming Data Pipelines
Streaming data pipelines involve moving data in real-time as it is being generated. This means that data is processed and analyzed as soon as it is collected, providing businesses with real-time insights.
Pros:
- Real-time processing and analytics allow businesses to make timely decisions based on the most up-to-date data.
- It can identify and address issues or opportunities in real-time, improving overall business performance.
- Real-time data can be used for personalization and targeting, making it beneficial for industries such as marketing and advertising.
Cons:
- Streaming data pipelines require more advanced technology and infrastructure, which may not be suitable for all businesses.
- It can be more expensive compared to batch processing, as real-time data analysis requires more resources.
- Handling large amounts of streaming data can lead to system overload and affect performance if not managed properly.
Hybrid Data Pipelines
Hybrid data pipelines combine the benefits of both batch and streaming data pipelines. They use batch processing for data that does not require real-time insights and streaming processing for time-sensitive data.
Pros:
- Hybrid data pipelines provide businesses with the best of both worlds, allowing them to handle both real-time and non-real-time data efficiently.
- They are scalable and flexible, making them suitable for businesses of all sizes.
- By combining batch and streaming processing, hybrid pipelines can reduce costs and improve efficiency.
Cons:
- Implementing and maintaining hybrid data pipelines can be complex and require specialized skills and resources.
- Companies may need to invest in advanced technology and infrastructure to support both types of data processing.
- Data integration and compatibility issues may arise when combining batch and streaming processes, leading to delays and errors.
Implementation of Data Pipelines in Different Industries
Data pipelines have become an essential part of modern-day businesses, and their implementation has been widespread across various industries. Let’s take a look at how data pipelines are being used in different sectors.
E-commerce and Retail
E-commerce and retail businesses deal with large volumes of data, from customer transactions to inventory management. Data pipelines help these businesses manage and analyze their data efficiently, providing them with insights on customer behavior, sales trends, and inventory levels.
Real-time data analysis can also be beneficial for e-commerce businesses, as it allows them to personalize product recommendations and target customers based on their online behavior.
Healthcare
The healthcare industry is another sector that generates vast amounts of data, from patient records to medical research. Data pipelines enable healthcare providers to store and analyze this data securely, improving patient care and outcomes.
Real-time analytics can also be crucial in the healthcare industry, where quick decision-making can save lives. For example, monitoring real-time patient data can alert doctors to any critical changes in a patient’s condition, allowing them to take immediate action.
Banking and Finance
Data is at the heart of the banking and finance industry, and data pipelines play a crucial role in managing and analyzing this data. From processing and analyzing financial transactions to fraud detection, data pipelines provide banks and financial institutions with the ability to handle large volumes of data accurately and efficiently.
Real-time analytics can also be beneficial in the finance sector, particularly in stock trading, where timely decisions can have a significant impact on profits and losses.
Marketing and Advertising
Marketing and advertising rely heavily on customer data to create targeted campaigns and measure their effectiveness. Data pipelines allow businesses to collect, process, and analyze customer data from various sources such as social media, website traffic, and CRM systems.
Real-time analytics can also help marketing and advertising teams track campaign performance and make necessary adjustments in real-time, improving overall ROI.
Manufacturing
The manufacturing industry has seen significant advancements in technology, leading to an increase in the amount of data generated. Data pipelines enable manufacturers to handle this data efficiently, providing them with insights on supply chain management, production processes, and inventory levels.
Real-time analytics can also be beneficial in manufacturing, where data from sensors can be analyzed in real-time to identify any issues in the production process and prevent downtime.
Challenges and Solutions in Building and Maintaining Data Pipelines
While data pipelines come with many benefits, there are also challenges that businesses may face when building and maintaining them. Let’s take a look at some of these challenges and possible solutions.
Data Integration and Compatibility Issues
Data pipelines need to integrate data from various sources, and this can be challenging when dealing with different formats and structures. For example, data from different databases may have different schemas, making it difficult to merge them together.
To overcome this challenge, businesses can use data integration tools that can handle data from different sources and formats seamlessly. These tools often come with built-in connectors that make it easier to extract and transform data from different sources.
Data Security and Privacy Concerns
With the increasing amount of data being collected and stored, data security and privacy have become major concerns for businesses. Data pipelines need to ensure that sensitive data is encrypted and only accessible by authorized users.
To address this challenge, businesses can implement encryption and authentication methods to secure their data. This can include using SSL/TLS protocols to encrypt data during transmission and implementing user access controls to restrict access to sensitive data.
Complex Data Structures and Formats
Data pipelines often deal with complex data structures and formats, such as JSON, XML, or CSV files. Handling these complexities can be challenging and may require specialized skills and resources.
To overcome this challenge, businesses can use data transformation tools that can convert data into a standardized format that can be used for analysis. These tools can also help split large datasets into smaller chunks, making it easier to manage and process the data.
Data Pipeline Monitoring and Maintenance
Data pipelines need to be monitored regularly to ensure that they are functioning correctly and that any issues are identified and addressed promptly. This can be a time-consuming task, particularly for companies dealing with large volumes of data.
To make this process more efficient, businesses can set up automated alerts and notifications that will inform them of any issues or errors in the data pipeline. Regular testing and debugging should also be done to ensure that the data pipeline is running smoothly.
Future of Data Pipelines
As technology continues to advance, so does the role of data pipelines in managing and analyzing data. Here are some predictions for the future of data pipelines:
- Advancements in technology, such as edge computing and 5G networks, will enable faster and more efficient data processing.
- The adoption of artificial intelligence (AI) and machine learning (ML) will further automate the data pipeline process, making it more accurate and reliable.
- As the use of big data and the internet of things (IoT) continues to grow, data pipelines will play an even more critical role in handling and analyzing vast amounts of data.
- There will be an increased demand for real-time analytics as businesses strive to stay ahead of their competition and make timely decisions based on the latest data available.
- The role of data engineers, who are responsible for building and maintaining data pipelines, will become even more crucial as companies continue to rely on data-driven decision-making.
Conclusion
In today’s digital world, data is an essential asset for businesses, and its management and analysis have become increasingly important. Data pipelines provide an efficient and cost-effective solution for handling and processing vast amounts of data from different sources. They enable businesses to gain valuable insights from their data, leading to better decision-making and improved overall performance.
Data pipelines come with many benefits, including real-time processing and analytics, automation, scalability, and improved data quality. However, there are also challenges that businesses need to address when building and maintaining data pipelines. These challenges can be overcome with the use of data integration and transformation tools, as well as implementing security measures and regular monitoring.
As technology continues to advance, the role of data pipelines will only become more critical, and businesses that embrace this technology will have a competitive advantage in today’s data-driven world.