
Apache Flink is a powerful open-source framework for distributed stream and batch processing of big data. It was first introduced in 2014 at the Strata + Hadoop World conference and has since gained widespread popularity among data engineers and data scientists alike. With its innovative design and advanced features, Flink has become a game-changer in the world of real-time data processing.
In this article, we will delve into the world of Apache Flink, exploring its key features, use cases, and benefits. We will also discuss the challenges it addresses and how it compares to other popular data processing frameworks. So, let’s dive in and discover what makes Apache Flink a must-have tool in any data-driven organization.
Introduction to Apache Flink
What is Apache Flink?
Apache Flink is an open-source distributed data processing framework designed for high-performance stream and batch processing of big data. It is built on top of the core concepts of data streams and transformations, making it ideal for real-time data processing. Flink offers a unified programming model for both stream and batch data, allowing developers to build complex data pipelines with ease.
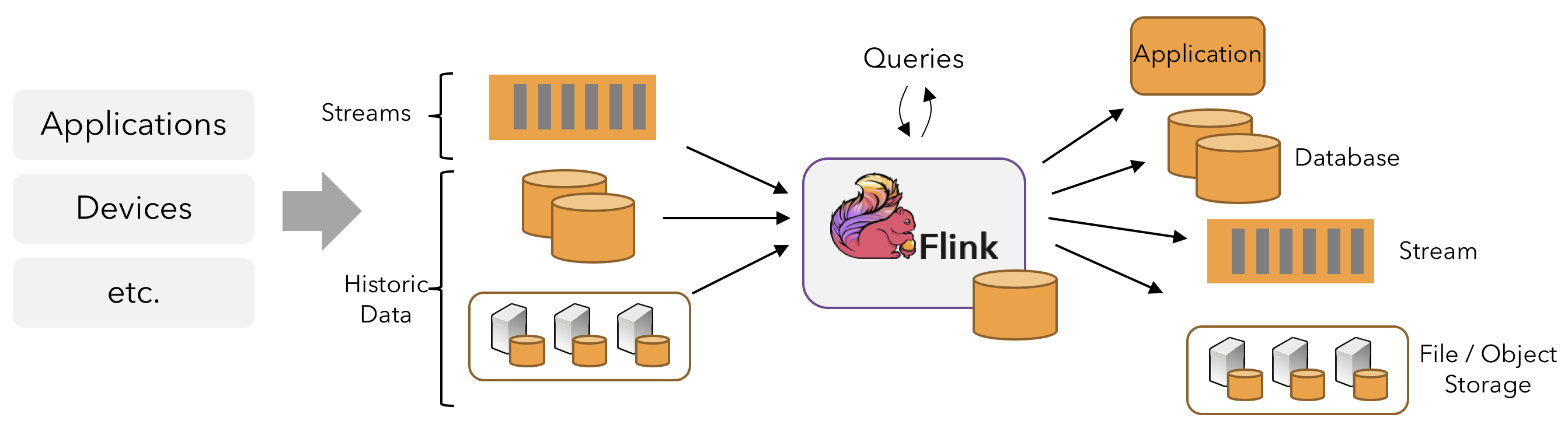
Apache Flink is a distributed data processing framework, available as open source, tailored for high-performance handling of both streaming and batch data processing tasks on a large scale
Brief history of Apache Flink
The origins of Apache Flink can be traced back to the Stratosphere research project at Technical University Berlin in 2009. The goal of this project was to develop a distributed data processing framework that could handle both batch and stream processing in a unified manner. In 2014, the project was donated to the Apache Software Foundation and became an Apache Incubator project. A year later, in 2015, Flink was promoted to a Top-Level Project (TLP) within the Apache community.
Since then, Apache Flink has evolved rapidly, adding new features and improving existing ones. It has gained widespread adoption in various industries, including e-commerce, finance, telecommunications, and more.
Why choose Apache Flink?
There are several reasons why Apache Flink has become a popular choice for real-time data processing. Some of the key benefits include:
- Unified Processing Model: As mentioned earlier, Flink offers a unified programming model for both stream and batch data, eliminating the need for separate tools and technologies.
- Low Latency: Flink is designed for low-latency data processing, making it suitable for applications that require real-time responses.
- Fault-Tolerance: Flink’s robust fault-tolerance mechanism ensures minimal data loss even in the event of failures.
- Scalability: With its native support for dynamic scaling, Flink can handle large amounts of data without compromising on performance.
- Advanced Windowing Capabilities: Flink offers various windowing options such as time-based, count-based, and session-based, allowing for efficient processing of different types of data.
- Native Iterations: Apache Flink is one of the few frameworks that natively supports iterative data processing, making it well-suited for machine learning and graph algorithms.
Key Features of Apache Flink
Stream and Batch Processing
One of the key features of Apache Flink is its ability to process data streams and batches simultaneously. This means that developers can use the same programming model for both real-time and historical data. Flink’s data processing engine is based on a streaming-first architecture, where batch processing is seen as a special case of stream processing. Let’s take a closer look at how Flink handles both types of data.

Apache Flink excels in its capability to process both streaming data and batch data concurrently, distinguishing it as a versatile data processing framework
How does Apache Flink handle both stream and batch data?
Flink represents batch data as bounded streams, which are essentially streams with a defined start and end. These bounded streams are processed in the same way as unbounded streams, making it possible to build hybrid applications that require both real-time and historical data.
In Flink, data is represented as a continuous stream of events, and transformations are applied incrementally on this stream. When processing batch data, Flink processes each batch as a separate event, ensuring that the results are consistent with traditional batch processing frameworks.
Advantages of processing both types of data together
The ability to process both stream and batch data in a unified manner offers several advantages:
- Simplified Architecture: Since there is no need for separate tools and technologies, the overall system architecture becomes simple and manageable.
- Reduced Development Time: With a unified programming model, developers can focus on building the logic of their data pipeline without worrying about the underlying infrastructure.
- Real-Time Insights from Historical Data: By combining real-time and historical data, organizations can gain real-time insights from their vast amounts of historical data, which was not possible before.
- Low Latency Updates: In certain use cases, it may be necessary to update results in real-time as new batch data becomes available. With Flink’s unified processing, this can be done efficiently without having to reprocess the entire batch.
Fault-Tolerance
Fault-tolerance is a crucial aspect of any data processing framework, especially when dealing with large volumes of data. Flink’s fault-tolerance mechanism is based on the concept of state checkpoints, which are periodically taken and stored in a reliable storage system.
How does Apache Flink ensure fault-tolerance?
Flink follows the principle of “exactly-once” processing, which guarantees that each event is processed exactly once, even in the event of failures. This is achieved by checkpointing the state of each operator at regular intervals. In case of a failure, the state can be restored from the last successful checkpoint, ensuring that no data is lost.
Moreover, Flink also supports externalized checkpoints, where the state has persisted to a durable storage system such as HDFS or Amazon S3. This not only ensures fault-tolerance but also allows for easy recovery in case of job failures or system crashes.
Comparison with other frameworks
Compared to other popular data processing frameworks like Apache Spark, Apache Storm, or Kafka Streams, Flink’s fault-tolerance mechanism offers stronger guarantees. While Spark and Storm only guarantee at-least-once processing, Flink’s “exactly-once” semantics make it more suitable for applications that require high data accuracy.
Low Latency
With its streaming-first architecture and native support for real-time data processing, Apache Flink offers low latency processing capabilities. This means that data is processed, and results are generated in near real-time, making Flink ideal for applications that require quick responses.
How does Apache Flink achieve low latency?
Flink uses a distributed engine model that deploys operators (tasks) to a cluster of machines. These operators run in parallel, and data is streamed between them using a network stack that is optimized for low latency. Additionally, Flink’s native iterative processing capabilities eliminate the need for data shuffling between iterations, further reducing latency.
Use cases for low latency processing
Low latency processing is crucial in applications that require real-time responses, such as fraud detection, risk analysis, or monitoring of financial markets. With its ability to process both stream and batch data, Apache Flink can provide real-time insights from both recent and historical data, making it a powerful tool for various use cases.
Native Iterations
Flink is one of the few frameworks that natively supports iterative data processing. This means that developers can write loops within their data processing logic without having to worry about performance issues.
Explaining native iterations in Apache Flink
In traditional distributed data processing frameworks like Spark or Hadoop, iterative algorithms are implemented using a series of map-reduce jobs, which involves writing intermediate results to disk after each iteration. This approach can become inefficient when dealing with large datasets and complex computations.
In Flink, iterations are treated differently, where the input data is kept in memory throughout the entire iteration. This reduces the overhead of writing data to disk and reading it back, resulting in faster execution times.
Benefits of native iterations
The native iterative processing in Apache Flink offers several advantages:
- Faster Execution: As mentioned earlier, avoiding disk I/O makes the iterative processing significantly faster.
- Reduced Overheads: Since data is stored in memory, there is no need for serialization and deserialization, reducing the overheads associated with it.
- Better Resource Utilization: With native iterations, Flink can utilize the available resources more efficiently, resulting in better resource utilization and improved performance.
Dynamic Scaling
With the increasing volume of data being processed in organizations, the ability to scale dynamically has become essential. Apache Flink offers native support for dynamic scaling, allowing for the addition or removal of worker nodes on-demand, based on the workload.
What is dynamic scaling?
Dynamic scaling refers to the ability to add or remove computing resources based on the current workload. In the context of Flink, this means adding or removing worker nodes from the cluster, depending on the volume of data being processed.
Why is it important in data processing?
Dynamic scaling offers several benefits, such as:
- Cost Optimization: By adding more computing resources when needed and removing them when not, organizations can optimize their costs by paying only for the resources they require.
- Efficient Resource Utilization: With dynamic scaling, the available resources are utilized efficiently, avoiding overprovisioning or underutilization.
- Improved Performance: Adding more workers allows for better parallelization, resulting in faster data processing times.
Advanced Windowing Capabilities
Apache Flink offers various windowing options, allowing for efficient processing of different types of data. A window is a subset of the data stream that is used for applying transformations or aggregations. There are three types of windows in Flink – time-based, count-based, and session-based.
Types of windowing in Apache Flink
Time-based Windows
Time-based windows group events based on a fixed time interval. For example, a 5-minute tumbling window will group all events that occur within a 5-minute interval.
Count-based Windows
Count-based windows group a fixed number of events before firing the window. For example, a tumbling window with a count of 100 will fire after every 100 events.
Session Windows
Session windows group events based on their session ID. A session is a period of activity separated by a defined gap. For example, a session window with a gap of 10 minutes will group all events from the same session within a 10-minute interval.
Use cases for different windowing techniques
Different types of windowing in Apache Flink cater to different use cases:
- Time-Based Windows: These are useful when dealing with streaming data that arrives at regular intervals, such as stock market data or sensor readings.
- Count-Based Windows: Count-based windows are useful when processing data in batches, where the number of events can vary for each batch.
- Session Windows: Session windows are ideal for applications where data is grouped based on user sessions, such as website clickstream data or online gaming data.
Use Cases of Apache Flink
Fraud Detection
Fraud detection has become a critical use case for many organizations, especially in finance and e-commerce industries. With the increasing volume of transactions, identifying fraudulent activities in real-time has become a challenge. This is where Apache Flink comes into play.
How can Apache Flink identify fraudulent activities in real-time?
Flink’s low latency processing capabilities make it suitable for fraud detection applications. By analyzing patterns and anomalies in real-time transaction data, Flink can detect potentially fraudulent activities as they occur. Moreover, its fault-tolerance mechanism ensures that no data is lost, and all events are processed accurately.
Benefits of using Flink for fraud detection
The use of Apache Flink for fraud detection offers several benefits:
- Real-Time Detection: By processing data in real-time, potentially fraudulent activities can be caught and prevented before significant damage is done.
- Accuracy: Flink’s “exactly-once” semantics guarantee accurate results, making it suitable for applications where precision is crucial.
- Scalability: As the volume of transactions grows, Flink’s dynamic scaling capabilities allow for efficient processing without compromising on performance.
IoT Data Processing
With the rise of the Internet of Things (IoT), organizations are facing the challenge of handling large volumes of real-time data from various devices. This is where Apache Flink’s streaming-first architecture and low latency processing capabilities can be leveraged.

Due to the proliferation of the Internet of Things (IoT), organizations are grappling with managing vast amounts of real-time data originating from diverse devices
Challenges in processing IoT data
IoT devices generate a continuous stream of data, which must be processed and analyzed in real-time to gain insights. Traditional batch processing systems are not suitable for this use case as they cannot handle the high data velocity and don’t provide timely insights.
How can Apache Flink handle real-time stream data from IoT devices?
Flink’s native support for stream processing makes it ideal for applications that require real-time insights from IoT data. Its low latency processing capabilities ensure that data is processed and analyzed in near real-time, allowing for quick responses and decision-making.
Recommendation Systems
Recommendation systems have become an integral part of many businesses, especially in e-commerce, media, and entertainment industries. These systems use machine learning algorithms to analyze customer behavior and make personalized recommendations in real-time. Apache Flink’s advanced features make it an ideal candidate for building recommendation systems.
How Apache Flink can be used for real-time personalized recommendations?
Flink’s native iterative processing capabilities make it suitable for building recommendation systems that require complex computations. With its low latency processing, Flink can analyze user behavior in real-time and make personalized recommendations instantly. Moreover, its fault-tolerance mechanism ensures that no data is lost in case of failures, resulting in accurate recommendations.
Comparison with other recommendation systems
Compared to traditional recommendation systems built on batch processing frameworks, Flink offers several advantages:
- Faster Response Time: With its low latency processing, Flink can generate recommendations in real-time, providing a better user experience.
- Scalability: As the number of users and items grows, Flink’s dynamic scaling capabilities allow for efficient processing of large volumes of data.
- Better Accuracy: Flink’s “exactly-once” semantics guarantee accurate results, making it more reliable for applications where precision is crucial.
Advertising Analytics
Real-time advertising analytics is yet another popular use case for Apache Flink. Advertisers need to analyze vast amounts of data in real-time to target ads to the right audience and optimize their campaigns. This is where Flink’s low latency processing and advanced windowing capabilities come into play.
Role of Apache Flink in real-time advertising analytics
With its low latency processing, Flink can process ad targeting data in real-time, allowing advertisers to reach out to potential customers quickly. Moreover, its advanced windowing techniques make it possible to analyze data across different timeframes, helping in campaign optimization.
Benefits of using Flink for ad targeting and optimization
The use of Apache Flink in real-time advertising analytics offers several benefits:
- Efficient Campaign Optimization: By analyzing data in real-time, advertisers can make quick decisions and optimize their campaigns for better results.
- Accurate Targeting: With its “exactly-once” semantics, Flink ensures that ad targeting data is processed accurately, resulting in better-targeted ads.
- Dynamic Scaling: Flink’s native support for dynamic scaling allows for efficient processing of large volumes of ad targeting data.
Comparison with Other Data Processing Frameworks
Apache Flink is not the only open-source framework available for distributed data processing. Let’s take a look at how it compares toother popular frameworks like Apache Spark and Apache Storm.
Apache Flink vs. Apache Spark
Programming Model
| Apache Flink | Apache Spark |
|---|---|
| Supports both batch and streaming processing. | Initially designed for batch processing, with later support for streaming. |
| Provides a more expressive API for complex event-time processing. | Offers a simpler programming model compared to Flink. |
Performance
- Apache Flink:
- Optimized for low-latency, high-throughput processing.
- Better suited for applications requiring event-time processing.
- Apache Spark:
- Initially focused on in-memory processing for batch jobs.
- Resilient Distributed Dataset (RDD) model may introduce overhead for streaming applications.
Fault Tolerance
- Apache Flink:
- Guarantees exactly-once state consistency.
- Checkpointing mechanism ensures fault tolerance without data loss.
- Apache Spark:
- Provides fault tolerance through lineage information.
- Limited fault tolerance for streaming applications.
Apache Flink vs. Apache Storm
Processing Model
| Apache Flink | Apache Storm |
|---|---|
| Supports batch processing, iterative processing, and graph processing. | Primarily designed for real-time stream processing. |
| Provides event-time processing support out of the box. | Requires additional components for event-time processing. |
State Management
- Apache Flink:
- Built-in mechanisms for managing application state.
- Supports different state backends for fault tolerance.
- Apache Storm:
- External solutions like Apache Kafka or Apache Cassandra are needed for state management.
- Relies on the Trident extension for stateful processing.
Scalability
- Apache Flink:
- Dynamic scaling for both operators and state.
- Better suited for handling large-scale computations.
- Apache Storm:
- Scaling requires manual intervention.
- Not as efficient as Flink for handling massive workloads.
In conclusion, while Apache Flink, Apache Spark, and Apache Storm all have their strengths and weaknesses, Apache Flink stands out for its seamless support for both batch and streaming processing, low-latency capabilities, and advanced features like event-time processing and session windows. It is well-suited for use cases that require real-time analytics, complex event processing, and high fault tolerance.
Apache Flink in Internet of Things (IoT) Applications
Apache Flink’s capabilities extend to a wide range of use cases, including Internet of Things (IoT) applications. IoT devices generate massive amounts of data that need to be processed and analyzed in real-time to extract valuable insights. Let’s explore how Apache Flink can be utilized effectively in IoT applications.
Real-time Data Processing from IoT Devices
IoT devices are constantly generating streams of data related to various parameters such as temperature, humidity, location, and more. Apache Flink’s ability to process streaming data in real-time makes it well-suited for handling the continuous influx of data from IoT devices. By ingesting, processing, and analyzing this data on-the-fly, Flink enables organizations to make timely decisions based on the insights gained.
- Low Latency Processing: Apache Flink’s low latency processing ensures that data from IoT devices is analyzed quickly, allowing for instant responses or actions based on the processed information.
- Complex Event Processing: Flink’s support for event-driven applications enables the detection of complex patterns and correlations within the incoming IoT data streams, leading to proactive decision-making.
- Integration Capabilities: Flink seamlessly integrates with popular messaging systems like Apache Kafka, MQTT, and more, making it easier to collect data from diverse IoT devices and platforms.
Stateful Stream Processing for IoT Data Analytics
In IoT applications, maintaining the state of the data stream is crucial for tasks such as anomaly detection, predictive maintenance, and real-time monitoring. Apache Flink’s state management capabilities allow developers to store and access the state of the streaming data efficiently, ensuring consistency and accuracy in IoT data analytics.
- Savepoints and Checkpoints: Flink provides mechanisms for creating savepoints and checkpoints, which enable fault tolerance by storing the state of the streaming application periodically. In case of failures, the application can recover its state from these checkpoints, ensuring data integrity.
- Queryable State: Apache Flink’s queryable state feature allows external applications to query the state of the streaming application in real-time. This capability is beneficial for interactive analytics and dynamic decision-making based on the IoT data.
- Time Management: With Flink’s event-time processing and windowing capabilities, IoT data streams can be efficiently managed based on timestamps, enabling timely aggregation, analysis, and visualization of the data.
Scalability and Elasticity for IoT Workloads
As the number of IoT devices and data volume grows, scalability becomes a critical requirement for IoT data processing frameworks. Apache Flink’s native support for dynamic scaling and elasticity ensures that IoT applications can handle varying workloads and data volumes effectively.
- Dynamic Resource Allocation: Flink’s dynamic resource allocation feature allows automatic adjustment of resources based on the workload, ensuring efficient utilization of computing resources for processing IoT data.
- Efficient State Handling: Flink’s ability to scale both operators and state horizontally enables distributed processing of IoT data streams across multiple nodes, enhancing throughput and reducing processing time.
- Fault Tolerance at Scale: In IoT applications where data integrity is paramount, Apache Flink’s fault-tolerance mechanisms play a crucial role. By ensuring exactly-once processing semantics and reliable state management, Flink delivers high availability and fault tolerance for large-scale IoT deployments.
In summary, Apache Flink’s robust stream processing capabilities, fault tolerance mechanisms, and scalability features make it a powerful choice for building real-time analytics solutions for IoT applications. By leveraging Flink’s strengths in processing streaming data from IoT devices, organizations can unlock valuable insights, enhance decision-making processes, and drive innovation in the rapidly evolving IoT landscape.
Conclusion
In conclusion, Apache Flink emerges as a versatile and high-performance framework for real-time data processing, offering advanced features tailored to the requirements of modern streaming applications. From supporting complex event processing and stateful stream analytics to providing fault tolerance, scalability, and seamless integration with other data sources, Flink excels in diverse use cases spanning recommendation systems, advertising analytics, and Internet of Things applications.
By harnessing the capabilities of Apache Flink, organizations can gain a competitive edge through faster insights, more accurate predictions, and agile decision-making based on real-time data streams. Whether it’s personalizing recommendations for customers, optimizing advertising campaigns, or analyzing data from IoT devices, Apache Flink proves to be a robust foundation for building scalable, reliable, and efficient stream processing solutions. As the demand for real-time analytics continues to rise across industries, Apache Flink stands out as a leading choice for empowering data-driven innovation and driving business growth in today’s fast-paced digital era.